This is a reference page for a youtube video.
Here you will find some code examples and the video transcript.
Channel: https://www.youtube.com/@DoCodeDo
https://www.youtube.com/watch?v=Sao9D25PkMs
I hope this video helps you to to learn and improve your skills so you can use it in a real project and interviews.
Codes
TrustScorerAlgorithm example
class TrustScorerAlgorithm {
static get name() {
throw 'Should implement on subclass'
}
static get version() {
throw 'Should implement on subclass'
}
static shouldRunFor(company) {
throw 'Should implement on subclass'
}
perform(scoreAlgorithmRun) {
context = generateContext(scoreAlgorithmRun.company)
resulting_score = evaluateContext(context)
finishProcessing(scoreAlgorithmRun, context, resulting_score)
}
generateContext(company) {
throw 'Should implement on subclass'
}
evaluateContext(context) {
throw 'Should implement on subclass'
}
}
class Alg1V1 extends TrustScorerAlgorithm {
static name() {
return 'alg1'
}
static version() {
return 'v1'
}
static shouldRunFor(company) {
// Execute some conditionals
return true
}
generateContext(company) {
// Consult external services or databases
newData = AwesomeAPI.getSecretData(company.name)
return { company: company, newData: newData }
}
evaluateContext(context) {
// analyzes the context
return 'positive'
}
}
console.log((new Alg1V1()).generateContext())
DSL concept
algorithm do
name "alg1"
version "v1"
should_run_for do |company|
# your conditionals
true
end
generate_context do |company|
new_data = AmazingAPI.get_secret_data(company.name)
{ company:, new_data: }
end
evaluate_context do |context|
# analyzes the context
:positive
end
end
Javascript functions
export const NAME = 'alg1'
export const VERSION = 'v1'
export function shouldRunFor(company) {
// Execute some conditionals
return true
}
export function generateContext(company) {
// Consult external services or databases
newData = AwesomeAPI.getSecretData(company.name)
return { company: company, newData: newData }
}
export function evaluateContext(context) {
// analyzes the context
return 'positive'
}
System Architecture: Practical Example Video Transcript
We will start with the requirements, move on to the overall system architecture, and include some implementations ideas using patterns and language specific features.
Let’s start by describing our business requirements.
Requirements
Funcional requirements
Scoring Engine
We need to build an automated trust score system
that evaluates companies.
Giving it positives and negative scores
In order to be able to do that
This system will execute one or more scoring algorithms,
that are independent from each other,
can evaluate any logic
and use other services or databases.
Once completed, each algorithm will produce a positive or negative conclusion score.
At the end of a company’s trust evaluation, the company will have it’s own trust score containing positive and negative points
This information can be used by other parts of our system,
More requirements
- The system should be capable of processing multiple evaluations concurrently.
- A single Score evaluation should take no more than an 10 minutes to finish. Otherwise, it should timeout.
- Also, the algorithms used to evaluate a specific company are chosen in runtime according to customizable conditions such as the company type or shareholders members.
- We want to quickly retrieve the scoring results and logs.
- It also should be possible track the execution times for the entire evaluation and for each algorithm
- Note that, over time, algorithms may change, be removed, or new ones may be created
- And for a specific Score Evaluation, some external services may be unavailable. So some algorithms may not reach a conclusion.
Score Evaluation Log
With these considerations, for each Score Evaluation Run, we want to log:
- Which algorithms were executed at the time
And, for each algorithm log:
- We want to save any relevant data used for the decision
By reviewing these logs, we should be able to re-execute the algorithm and obtain the same resulting score that was calculated at the time of execution.
So it’s always possible to review how each score were decided.
The Architecture
Components and Interactions
With these requirements in mind, let’s design our system architecture.
In order to be able to achieve the batch processing and keep our expected processing time, we will use a queue to distribute the scoring evaluations across multiple workers that can execute in parallel.
Each trust score evaluation for a company will be handled by a TrustScorer worker.
This worker alone could execute all the algorithms and save the logs and results.
However, this approach could be time-consuming and would make it challenging to debug the execution of a specific algorithm. Since the algorithms are independent of one another, it should also be straightforward to parallelize their execution.
We can achieve this by changing the TrustScorer to use threads. While this approach could work, it may make error handling and debugging specific algorithms more complex.
Instead, we can use an additional queue and delegate the execution of each algorithm to specific workers, allowing them to run in parallel.
For this project, we’ll discuss an implementation that utilizes this second queue to process each algorithm concurrently using TrustScorerAlgorithm workers.
Depending on the framework you’re using, setting up these queues and workers should be straightforward.
You definitely doesn’t want to skip implementation discussion for this TrustScorerAlgorithm class. It’s cool, clean, it makes your life easier. More on that later, in this video.
API: The entrypoint
Let’s talk about the entrypoint of our engine.
If you want to use a separate service, you can communicate between services in many ways.
But I believe that even if you use other messaging solutions you will at least have some basic API like this one:
-
POST
/score_evaluations– An endpoint to create score evaluations- Receives an array with Companies
- Returns an array of ScoreEvaluations – with a "processing pending status"
-
GET
/score_evaluations/:id– This other endpoint feches a score evaluation by id- it Returns the entire Score Evaluation with data like
- the company snapshot
- And the results
The alternative: full monolith
You don’t necessarily need to create a separate service. You could implement this within your existing app.
Depending on the technology and libraries you’re using, you could isolate your logic in a module or, if you’re using Rails, in an engine.
With this architecture and a well-planned implementation, you can migrate to a separate service later if the need arises.
Implementation
Now, let’s discuss some key aspects of the implementation, starting with our entities and relationships.
Entities and Relationships
We have a:
- CompanySnapshot – Stores the data of the evaluated company
- Score evaluation – Tracks a score evaluation job execution.
- Score algorithm run – Tracks the execution of a specific algorithm.
Here’s how they are related to each other.
One score evaluation has one company and a company has one score evaluation.
This relationship is essential because, as the company data may change, it’s important to save the current state of the company for each run.
One score evaluation has many score algorithm runs, one for each algorithm that should run for the individual evaluation.
Of course, depending on your database and normalization used to store these entities you may save everything in one single document or use more tables or collections.
Entities Details
Let’s check some key attributes of each entity
A CompanySnapshot has fields like
- Name
- National ID
- Type (LLC, Corp, …)
- Business Description
- Members Name/Document ID – [ { name: , document: }]
Remember, we must always follow compliance policies when storing personal data
ScoreEvaluation – Has fields like
- started_at:
- finished_at
- status (waiting/processing/processed)
- positive_score
- negative_score
- And some caching like
- a count for the algorithms that should run
- a count for the algorithms that has successfully run
ScoreAlgorithmRun – Logs the execution of a specific algorithm.
- algorithm_name
- algorithm_version
- started_at
- finished_at
- status (waiting/processing/processed/timed_out)
- context_data (JSON) – used for the execution
- resulting_score (positive/negative)
Code
Now, considering this architecture,
Let’s dive into the implementation for the TrustScorer and it’s Algorithms.
I will assume the queueing implementation is already solved by some library so we can focus on the business requirements.
TrustScorer
Starting with the TrustScorer
In order to enqueue a job
Some place in your single APP
or in the API endpoint
Will call a class method .evaluate_async(company) in the TrustScorer class that receives the company data
- Creates a
ScoreEvaluationsaves to the database - It also saves the company snapshot. Here, I reinforce that, even if you have a monolith, I recommend that you do not just reference the original company. You should save a snapshot of the current state of the company.
- Schedule the
ScoreEvaluationfor future timeout processing (we hope that this one never needs to to something) - Finally, it returns the
ScoreEvaluationdata
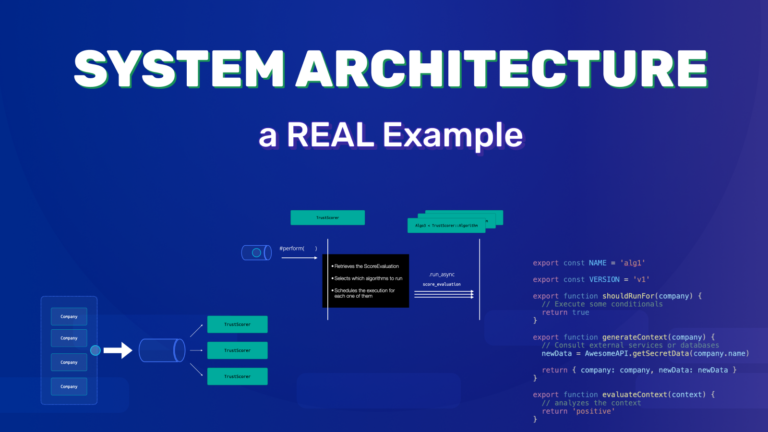
TrustScorer Worker
At some point in the future a TrustScorer worker will take the job and execute a perform instance method passing the score evaluation ID then:
- We can retrieve it from the database.
- Select which algorithms to run based on the company attributes
- Schedule the execution for each one of them
We do that by calling the .run_async class method for each Algorithm class. This method receives the score_evaluation entity that we’ve just retrieved from the database.
The .run_async method:
- Creates a ScoreAlgorithmRun for the specific algorithm
- And enqueues
Finishing the workflow for a TrustScorer Worker
TrustScorer Worker Timeout
There’s also a TrustScorer::TimeoutHandler
That will receive a score evaluation 10 minutes after it is created.
If everything has already been processed, no action will be taken.
Otherwise, it will complete the evaluation and algorithms with a timeout.
TrustScorer::Algorithm Worker
Just like before, at some point in the future, TrustScorer::Algorithm Worker will take the job.
- Run the specific logic for the current algorithm
- And updates all the relevant records with logs and results
- After that, the job execution, ends
Here are some interesting points
Depending on how it’s implemented, the update of the ScoreEvaluation could face race conditions due to the parallel processing of the algorithms.
In the worst case it would be correctly updated as finished when the timeout handler executes.
Also, we could use libraries designed to handle asynchronous workflows .
Some interesting points
- If you really need to have more control on timeouts, some things can be improved
- You may create a cronjob or
- Depending on the importance of this issue you may even need to impose validation rules in other parts of the system
- With this design should be easy implement custom instrumentation to generate logs, track when a job start/end or debug.
- Another interesting fact is that we maybe don’t even need the queue for the TrustScorer, we can directly execute and schedule the algorithms right from the API endpoint
- Also, depending on the data volume, you should plan your schemas and storage more carefully to improve storage space and data access. You may also want to use read database replicas.
- If you have doubts, suggestions or a complete different proposal on how to design this, leave a comment sharing your ideas.
Code
Now, the question is, how do we implement the TrustScorer::Algorithm class in order to be easy to create new algorithms:
- Name
- Version
- Conditions to choose which one to execute in runtime depending on company attributes
- In a way that we we don’t have replicated code (updates, logs and other common actions)
Let’s draft some potential implementations.
Using classes
Starting with a basic implementation here’s some pseudo code similar to javascript.
We have a TrustScorer::Algorithm base class that:
-
Has some class methods or properties that the subclasses must override
- name
- version
- shouldRunFor(company)
- Note that I don’t want to leave this with any default value. This force us to think about this criteria when creating new algorithms.
-
the
#performmethod is called when a job is executed. It is a template method that receives theScoreAlgorithmRunrecord.- it generates a context object for the algorithm rules to run
- calls the evaluateContext method passing the generated context
- finishes the processing by updating all the records
-
The
generateContextand theevaluateContextinstance methods should be implemented in the subclassesgenerateContext– uses the company data to generate a context for the decision. Here you can fetch external dataevaluateContext– uses the context to reach a conclusion
Example
It should be easy to create new algorithms, like in this example here.
To be able to use a new algorithm, you will need to update some other place like the TrustScorer class or a Specific Implementation to handle the algorithm list
depending on the language that you’re using,
You can use metaprogramming to avoid having to update multiple places each time you create a new algorithm.
DSL
Speaking of metaprogramming, you may want to take it a step further and implement a domain-specific language (DSL) for defining algorithms.
Creating your own business programming language.
With that, you will be able to specify your algorithms, just like you do in a spec test file.
Javascript
You can acomplish the same thing using javascript or change the architecture a little bit to not use classes for defining an algorithm.
You just need export functions in the algorithm file.
I haven’t described every detail, and the final implementation may look different, but this should be enough to convey the idea.
If you think a video that further explains a concept or demonstrates a specific part of the code would be helpful, feel free to leave a message.
I hope you enjoyed it.
See you later.
Subscribe to my newsletter!
I share content about Software Development & Architecture, Entrepreneurship and Lifelong Learning




